ARM通讯接口
0. C语言 volatile 关键字
- 编译器优化介绍:
由于内存访问速度远不及CPU处理速度,为提高机器整体性能,在硬件上引入硬件高速缓存Cache,加速对内存的访问。 - volatile总是与优化有关,编译器有一种技术叫做数据流分析,分析程序中的变量在哪里赋值、在哪里使用、在哪里失效,分析结果可以用于常量合并,常量传播等优化,进一步可以消除一些代码。但有时这些优化不是程序所需要的,这时可以用volatile关键字禁止做这些优化。
- volatile的本意是“易变的” 因为访问寄存器要比访问内存单元快的多,所以编译器一般都会作减少存取内存的优化,但有可能会读脏数据。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问;如果不使用valatile,则编译器将对所声明的语句进行优化。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错)
- 如果你对此外部设备进行初始化的过程是必须是像上面代码一样顺序的对其赋值,显然优化过程并不能达到目的。反之如果你不是对此端口反复写操作,而是反复读操作,其结果是一样的,编译器在优化后,也许你的代码对此地址的读操作只做了一次。然而从代码角度看是没有任何问题的。这时候就该使用volatile通知编译器这个变量是一个不稳定的,在遇到此变量时候不要优化。
例如:
volatile int *output=(volatile unsigned int *)0xff800000;//定义一个I/O端口
1. 串口通信原理
串口通信基本概念
通信中最重要的三个方面: 信息表示(编码)、解析方法(解码)、信息的传输方法。通信双方事先需要约定好信息的表示方法和解析方法,做到一致,否则信息不能有效传递。信号的传输方法是指经过编码后的通信信息如何在传输介质上传输的过程,传输方法与编解码方法无关。
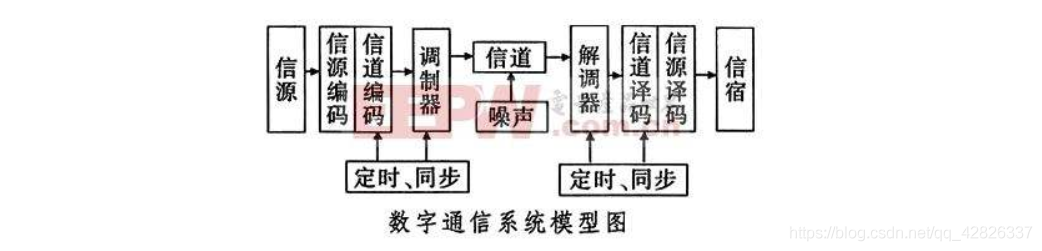
通信的过程:首先发送方先按照信息编码方式对有效信息进行编码(编程成可以在通信线路上传输的信号形态),编码后的信息在传输介质上进行传输,输送给接收方;最后接收方接收到编码信息后进行解码,解码后得到可以理解的有效信息。
同步通信和异步通信:
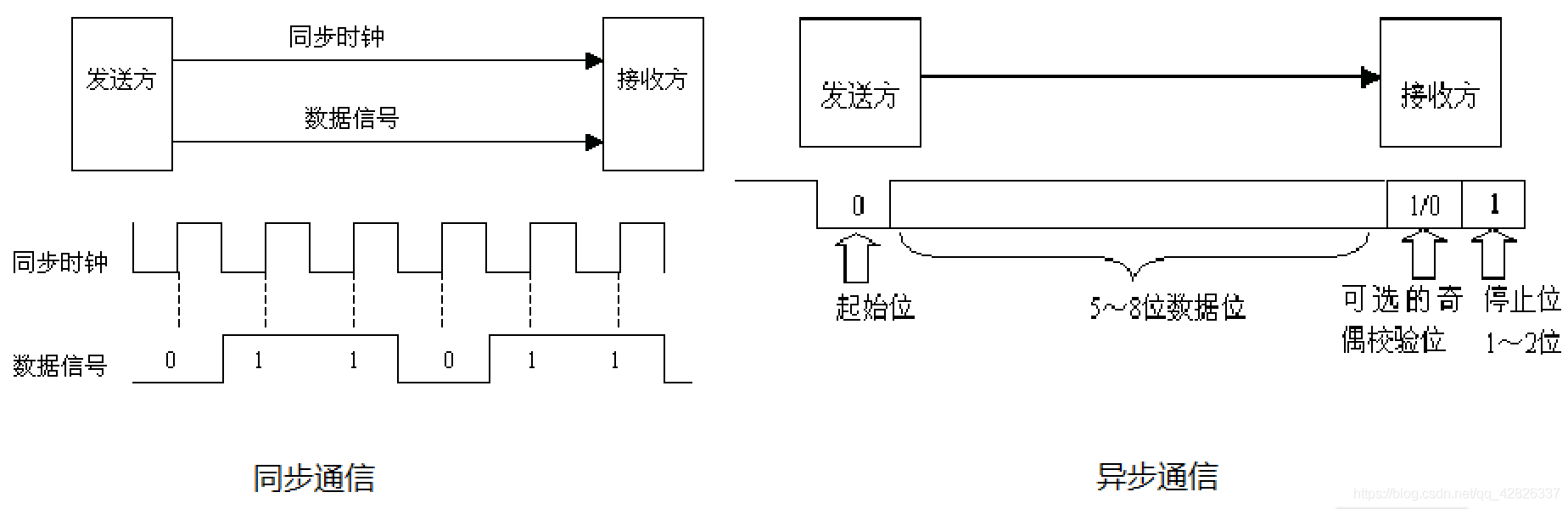
(1)同步通信:通信双方按照统一节拍工作,一般需要发送方给接收方发送信息同时发送时钟信号,接收方根据发送方给它的时钟信号来安排自己的节拍。(同步通信用在通信双方信息交换频率固定,或者经常通信时)
(2)异步通信:又叫异步通知。异步通信时接收方不必一直等待发送方,发送方需要发送信息时会首先给接收方一个信息开始的起始信号,接收方接收到起始信号后就认为后面紧跟着的就是有效信息,才会开始注意接收信息,直到收到发送方发过来的结束标志。(异步通信用在双方通信的频率不固定时)
(3)同步和异步的区别:发送方和接收方按照同一个时钟节拍工作就叫同步,发送方和接收方没有统一的时钟节拍、而各自按照自己的节拍工作就叫异步,同步一般带有一根时钟线,负责传输时钟,控制接收方的节拍(大部分情况下的判断依据)。
电平信号和差分信号:
(1)电平信号和差分信号是用来描述通信线路传输方式的,即通过什么方式在通信线路上来表达逻辑0或1。
(2)电平信号的传输线中有一个参考电平线(一般是GND),通过信号线上的信号电平和参考电平线的电压差决定信息表达是0或1。这种方式的传播一般容易受到外界干扰。
(3)差分信号的传输线中没有参考电平,所有都是信号线。通过信号线之间的电压差来表达逻辑0或1。由于两条信号线受到干扰环境的影响基本相同,因此两者之间受到的干扰可以在通过电压差计算时相互抵消。
串行通信和并行通信:
(1)串行、并行主要是考虑通信线的根数,就是发送方和接收方同时可以传递的信息量的多少。例如同时发送8位二进制数,对于电平信号,需要9根线(8根信号线+1根参考线);对于差分信号,需要16根线(2根组成1对,一共8对)。
(2)在实际使用时,串行接口应用更广泛,因为更省信号线,而且对传输线的要求更低、成本更低;而且串行时可以通过提高通信速度来提高总体通信性能,不一定非得要并行。2条线的串行通信方式每次只能传输1个二进制位。
最常用的搭配方式为:异步、串行、差分,譬如USB和网络通信。
波特率(bandrate):
指的是串口通信的速率,也就是串口通信时每秒钟可以传输多少个二进制位。譬如每秒种可以传输9600个二进制位(传输一个二进制位需要的时间是1/9600秒,也就是104us),波特率就是9600。一般最常见的波特率是9600或者115200(低端单片机如51常用9600,高端单片机和嵌入式SoC一般用115200)。通信双方必须事先设定相同的波特率这样才能成功通信,如果发送方和接收方按照不同的波特率通信则根本收不到。
起始位、数据位、奇偶校验位、停止位
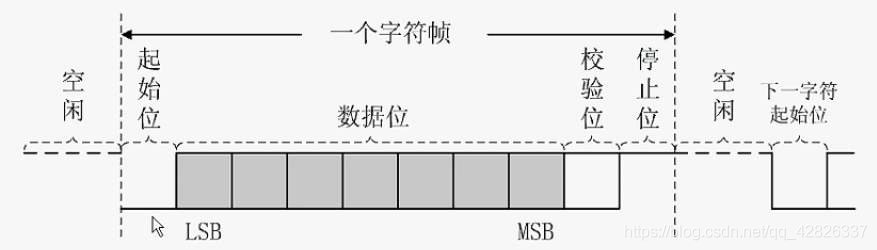
(1)串口通信时,收发是一个周期一个周期进行的,每周期传输n个二进制位。这一个周期就叫做一个通信单元,一个通信单元是由:起始位+数据位+奇偶校验位+停止位组成的(又叫做一帧)。
(2)起始位表示发送方要开始发送一个通信单元,起始位是串口通信标准事先指定的,是由通信线上的电平变化来反映的,也就是时序。数据位是一个通信单元中发送的有效信息位,也就是本次通信真正要发送的有效数据,大部分情况下数据位是8位,因为通过串口发送的文字信息都是ASCII码编码的,而ASCII码中一个字符刚好编码为8位。奇偶校验位是用来校验数据位,把待校验的有效数据逐个位的加起来,总和为奇数奇偶校验位就为1,总和为偶数奇偶校验位就为0。停止位是发送方用来表示本通信单元结束标志的,一般为1位。
总结:串口通信时因为是异步通信,所以通信双方必须事先约定好通信参数,这些通信参数包括:波特率、数据位、奇偶校验位、停止位(串口通信中起始位定义是唯一的,所以一般不用选择)。
通信方式(单工、双工、半双工)
(1)单工就是单方向传输,表示只能A发B收。
(2)双工就是双方同时收发,A发B收的同时也能B发A收。
(3)半双工就是只能单方向但是方向可以改变,A发B收或者B发A收(两个方向不能同时)。
本次课程中选用的FS4412开发板,使用了如下三种串行通讯:
双线: uart4 全双工 异步 TXD------RXD
RXD-----TXD
双线: i2c8 半双工 同步 SCL------SCL
SDA------SDA
三线: SPI*3 全双工 同步 SCL------SCL
MISO------MOSI
MOSI------MISO
2. 常见的电平标准
TTL电平
供电范围在0~5V。
对输出:大于2.4V是高电平;小于0.4V是低电平。
对输入:大于2V是高电平;小于0.8V是低电平。
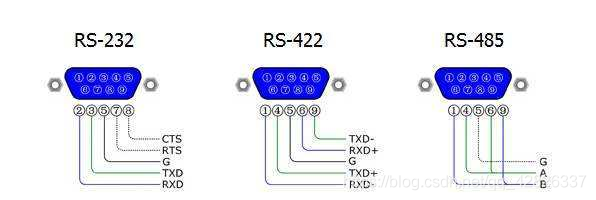
RS232
对输出:输出“1”时的电平应在-3~-15 V之间,输出“0”时的电平应在+3~+15 V之间。
对输入:输入电平在-3~-15 V之间被认为“1”,在+3~+15 V之间被认为“0”。
当线路上不传送数据(空闲)时,发送器输出为“1”。
双向传输,全双工通信,最高传输速率20kbps。
RS485
对输出:逻辑"1"以两线间的电压差为+2v ~ +6表示;逻辑"0"以两线间的电压差为-2V ~ -6V 表示。
对输入:A比B高200mV以上即认为是逻辑"1",A 比B 低200mV 以上即认为是逻辑"0"。
双向差分传输,半双工通信,最高传输速率10Mbps。
RS422
与RS485的电平标准相同,发送口与接收口不同,如若将其并连就变成了RS485。
相当于两个半双工的RS485构成了一个全双工通信,最高速率10Mbps。
3. 串口通信基本原理
通信线(RX TX GND)
(1)任何通信都要有信息传输载体,或者是有线的或者是无线的。串口通信是有线通信,是通过串口线来通信的。
(2)串口通信线最少需要2根(GND和信号线),可以实现单工通信,也可以使用3根通信线(Tx、Rx、GND)来实现全双工。一般开发板都会引出SoC上串口引脚直接输出的TTL电平的串口(X210开发板没有),插座用插针式插座,每个串口引出的都有3个线(Tx、Rx、GND),可以用这些插座直接连接外部的TTL电平的串口设备。
信息在信道上传输方式
串口通信的发送方每隔一定时间(时间固定为1/波特率,单位是秒)将有效信息(1或者0)放到通信线上去,逐个二进制位的进行发送。
接收方通过定时(起始时间由读到起始位标志开始,间隔时间由波特率决定)读取通信线上的电平高低来区分发送给我的是1还是0。依次读取数据位、奇偶校验位、停止位,停止位就表示这一个通信单元(帧)结束,然后中间是不定长短的非通信时间(发送方有可能紧接着就发送第二帧,也可能半天都不发第二帧,这就叫异步通信),接着发送第二帧·····
FIFO模式及其作用
对于典型的串口设计,发送/接收缓冲区只有1字节,因此每次发送/接收时只能处理1帧数据。在复杂的SoC中CPU的时钟远高于串口发送端,会导致CPU需要不断切换上下文(每发完1帧数据就需要重新切换回发送端),大大降低了速率。
如何像icache一样提供一个解决两者速率差异较大的方法?解决方案就是想办法扩展串口控制器的发送/接收缓冲区,例如将发送/接收缓冲器设置为64字节,CPU一次过来直接给发送缓冲区64字节的待发送数据,然后transmitter慢慢发,发完再找CPU再要64字节。但是串口控制器本来的发送/接收缓冲区是固定的1字节长度的,所以做了个变相的扩展,就是FIFO(first in first out),先进入缓冲区的先出来,从而不影响顺序。
CPU来一次直接给FIFO了64字节的内容,然后FIFO一个字节一个字节的给发送缓冲区,此时就不需要CPU的参与,大大提高了效率。
DMA模式及其作用
DMA direct memory access,直接内存访问。 DMA本来是DSP中的一种技术,DMA技术的核心就是在交换数据时不需要CPU参与,模块可以自己完成。DMA模式要解决的问题和上面FIFO模式是同一个问题,就是串口发送/接收要频繁的折腾CPU造成CPU反复切换上下文导致系统效率低下。
传统的串口工作方式(无FIFO无DMA)效率是最低的,适合低端单片机;高端单片机上CPU事物繁忙所以都需要串口能够自己完成大量数据发送/接收。这时候就需要FIFO或者DMA模式。FIFO模式是一种轻量级的解决方案,DMA模式适合大量数据迸发式的发送/接收时。
4. fs4412串口配置过程
4.1 配置前的分析
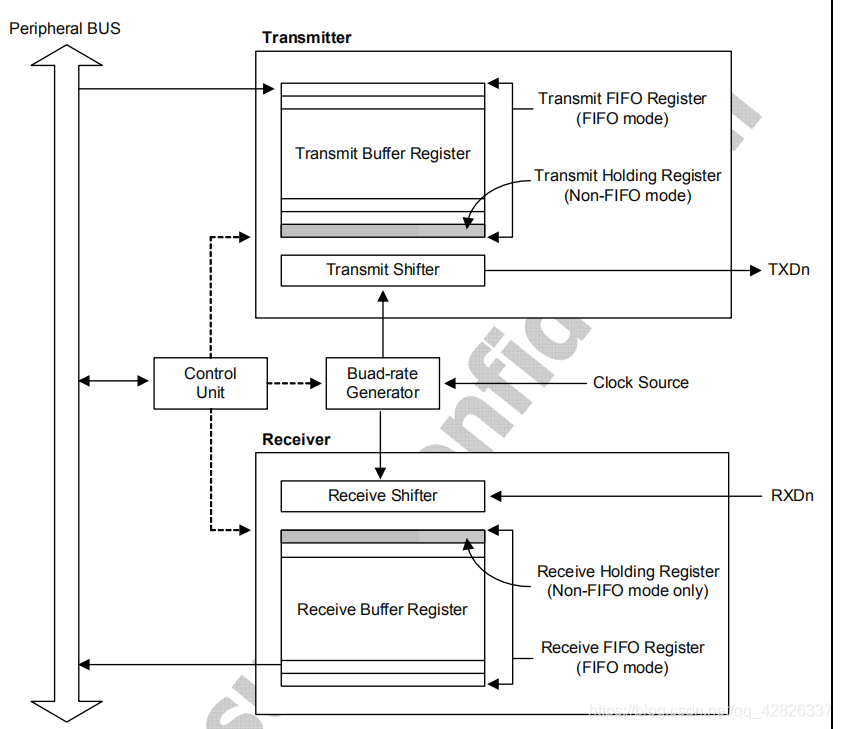
首先说明一下为什么串口叫UART,universal asynchronous reciver and transmitter,通用异步收发器,即可知UART的通信方式是异步的。
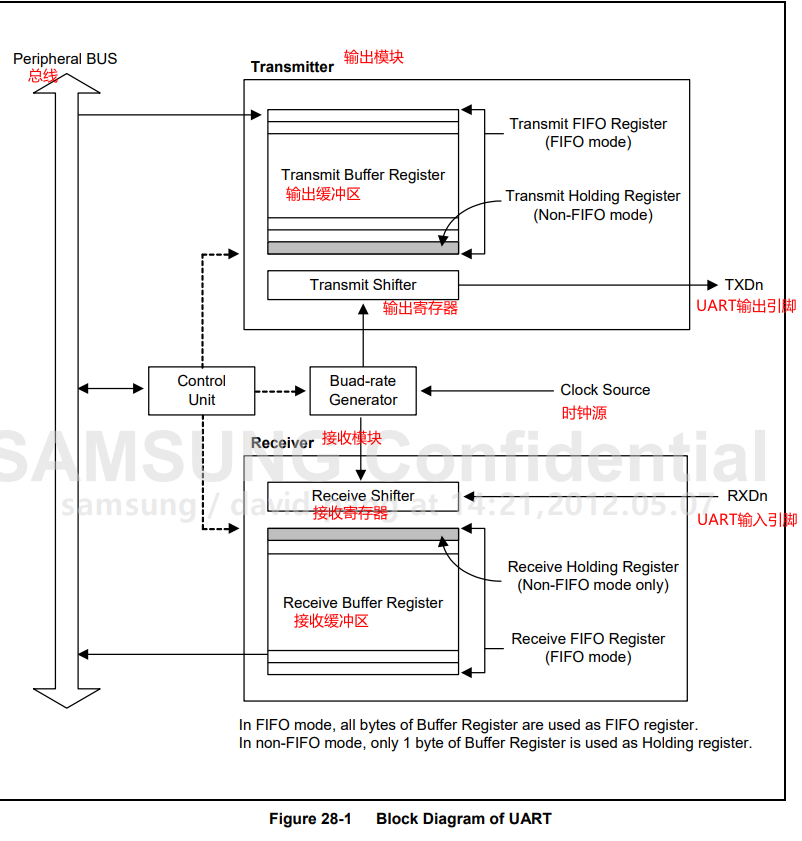
(1)从图中可以看出,整个串口控制器包含transmitter和receiver两部分,两部分功能彼此独立,transmitter负责4412向外部发送信息,receiver负责从外部接收信息到4412内部。
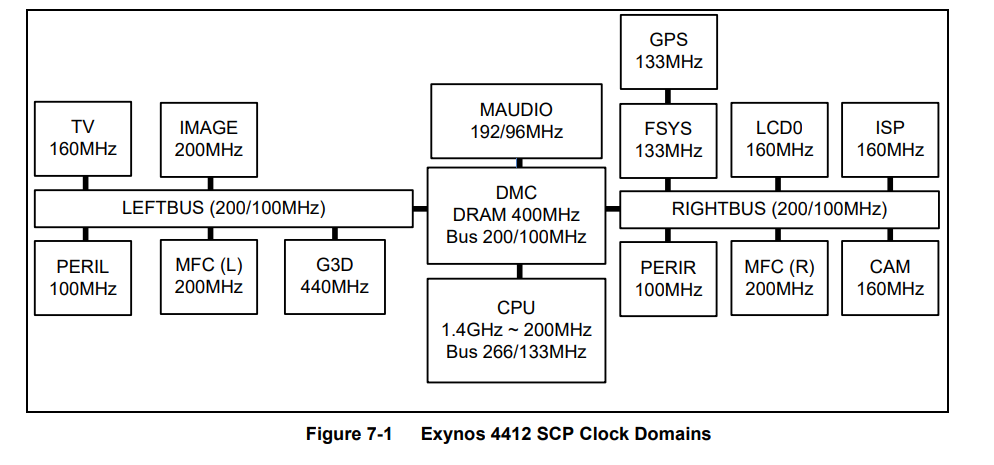
(2)从上面的的时钟部分可知,串口控制器是接在PERIL总线上的。对我们编程有影响的是:将来计算串口控制器的源时钟时是以PERIL总线来计算的。
(3)transmitter由发送缓冲区和发送移位器构成。 在发送信息时,首先将信息进行编码成二进制流,然后将一帧数据写入发送缓冲区,发送移位器会自动从发送缓冲区中读取一帧数据,然后自动移位(移位的目的是将一帧数据的各个位分别拿出来)将其发送到TX(发送端)通信线上。
(4)receiver由接收缓冲区和接收移位器构成。 当有人通过串口线向我发送信息时,信息通过RX(接收端)通信线进入我的接收移位器,然后接收移位器自动移位将该二进制位保存到我的接收缓冲区,接收完一帧数据后receiver会产生一个中断给CPU,CPU收到中断后即可知道receiver接收满了一帧数据,就会来读取这帧数据。
总结:发送缓冲区和接收缓冲区是关键。发送移位器和接收移位器的工作都是自动的,不用编程控制的,所以我们写串口的代码就是:首先初始化串口控制器(初始化的实质是读写寄存器,包括发送控制器和接收控制器),然后将要发送信息时直接写入发送缓冲区,要接收信息时直接去接收缓冲区读取即可。
串口通信分为发送/接收2部分。发送方一般不需要(也可以使用)中断即可完成发送,接收方必须(一般来说必须,也可以轮询方式接收)使用中断来接收。本实验采用轮询的方式接收,通过状态寄存器中有一个位叫发送缓冲区空标志,transmitter发送完成(发送缓冲区空了)就会给这个标志位置位,CPU就是通过不断查询这个标志位为1还是0来知道发送是否已经完成的。
4.2 时钟分析
从图中可以看出波特率的产生需要时钟的提供(Clock Source),所以transmitter和receiver都需要一个时钟信号。
由上述可得,源时钟信号是外部总线(PERIL,100MHz)提供给串口模块的,然后进到串口控制器内部后给波特率发生器(实质上是一个分频器),在波特率发生器中进行分频,分频后得到一个低频时钟,这个时钟就是给transmitter和receiver使用的。
4.3 UART 串口编程
4.3.1 UART 串口编程流程
初始化
管脚设置为UART模式
串口协议设置(奇偶校验位,数据位等)
串口波特率设置
发送字符
发送状态判断
发送
接收字符后环回
接收状态判断
接收
4.3.2 UART 串口编程实例
.global delay1s @.C文件要调用delay1s函数,因此要设置成全局函数
.text
.global _start @
_start:
b reset @0x00
ldr pc,_undefined_instruction @0x04
ldr pc,_software_interrupt
ldr pc,_prefetch_abort
ldr pc,_data_abort
ldr pc,_not_used
ldr pc,_irq
ldr pc,_fiq
_undefined_instruction: .word _undefined_instruction
_software_interrupt: .word _software_interrupt
_prefetch_abort: .word _prefetch_abort
_data_abort: .word _data_abort
_not_used: .word _not_used
_irq: .word _irq
_fiq: .word _fiq
reset:
ldr r0,=0x40008000 @设置异常向量表的起始地址为 0x40008000
mcr p15,0,r0,c12,c0,0 @ Vector Base Address Register
init_stack:
ldr r0,stacktop /*get stack top pointer*/
/********svc mode stack********/@设置各种模式的堆栈
mov sp,r0
sub r0,#128*4 /*512 byte for irq mode of stack*/
/****irq mode stack**/
msr cpsr,#0xd2 /* 初始化阶段要禁止IRQ,FIQ中断,I位=1,r位=1,mode位=10010 集合到一起就是d2 */
mov sp,r0
sub r0,#128*4 /*512 byte for irq mode of stack*/
/***fiq mode stack***/
msr cpsr,#0xd1
mov sp,r0
sub r0,#0
/***abort mode stack***/
msr cpsr,#0xd7
mov sp,r0
sub r0,#0
/***undefine mode stack***/
msr cpsr,#0xdb
mov sp,r0
sub r0,#0
/*** sys mode and usr mode stack ***/
msr cpsr,#0x10
mov sp,r0 /*1024 byte for user mode of stack*/
b main
delay1s: /* 延时1s函数 */
ldr r4,=0x1ffffff
delay1s_loop:
sub r4,r4,#1
cmp r4,#0
bne delay1s_loop
mov pc,lr
.align 4 /* 4字节对齐 */
/**** swi_interrupt handler ****/
stacktop: .word stack+4*512
.data
stack:
.space 4*512
.end
#define GPA1CON 0x11400020 #define ULCON2 0x13820000 #define UCON2 0x13820004 #define UBRDIV2 0x13820028 #define UFRACVAL2 0x1382002c #define UTXH2 0x13820020 #define UTRSTAT2 0x13820010 #define rGPA1CON (*(volatile unsigned int*)GPA1CON) #define rULCON2 (*(volatile unsigned int*)ULCON2) #define rUCON2 (*(volatile unsigned int*)UCON2) #define rUBRDIV2 (*(volatile unsigned int*)UBRDIV2) #define rUFRACVAL2 (*(volatile unsigned int*)UFRACVAL2) #define rUTXH2 (*(volatile unsigned int*)UTXH2) #define rUTRSTAT2 (*(volatile unsigned int*)UTRSTAT2) void uart_putc(char c); int main(int argc, const char *argv[]) { /* 设置GPA1控制器为UART模式 */ rGPA1CON &= ~(0xff<<0); //把寄存器的bit0~7全部清零 rGPA1CON |= 0x22<<0; //Rx,Tx /* 设置串口协议 */ rULCON2 = 0x03; //0校验位 ,8数据位,1停止位 rUCON2 = 0x05; //轮询模式 /* * 设置波特率: *UART时钟信号源的值为: *100Mhz= 100 000khz = 100 000 000hz *本实验波特率值位115200,DIV_VAL = 100000000/(115200*16) -1 = 54.25 -1 = 53.25 *UBRDIVn = 53 *UFRACVALn/16 = 0.25 ----> UFRACVALn = 4 */ rUBRDIV2 = 53; rUFRACVAL2 = 4; /* 发送状态判断 */ while(1) { uart_putc('c'); delay1s(); } return 0; } void uart_putc(char c) { while(!(rUTRSTAT2&0x02)); rUTXH2 = c; return; }
4.3.3 UART 芯片手册查询
找寻到 UART_AUDIO_TXD 和 UART_AUDIO_RXD
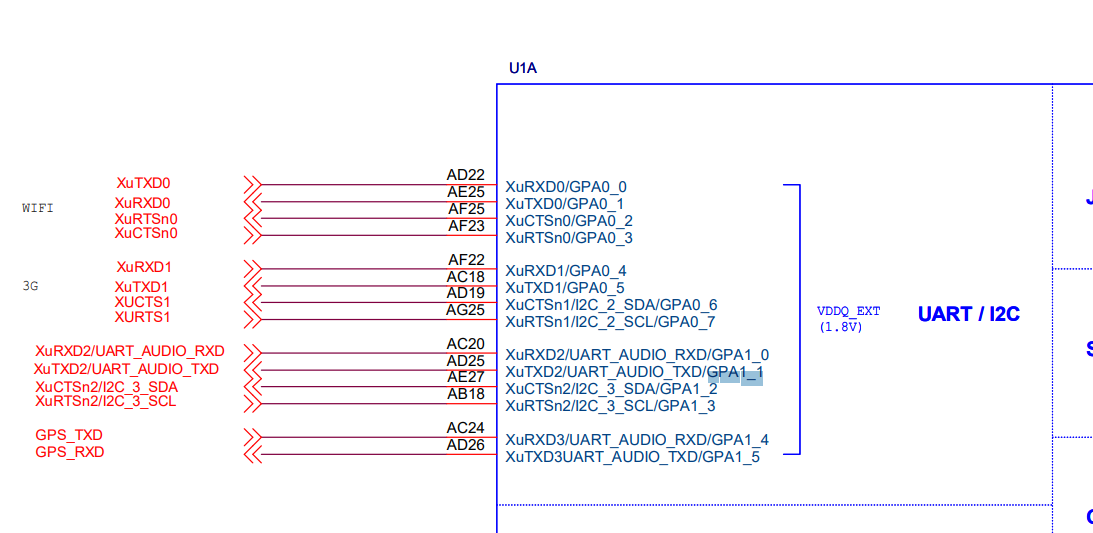
对应的芯片端接口 GPA1_1 和 GPA1_0,查找4412芯片手册,找到GPA1接口的设定GPA1CON
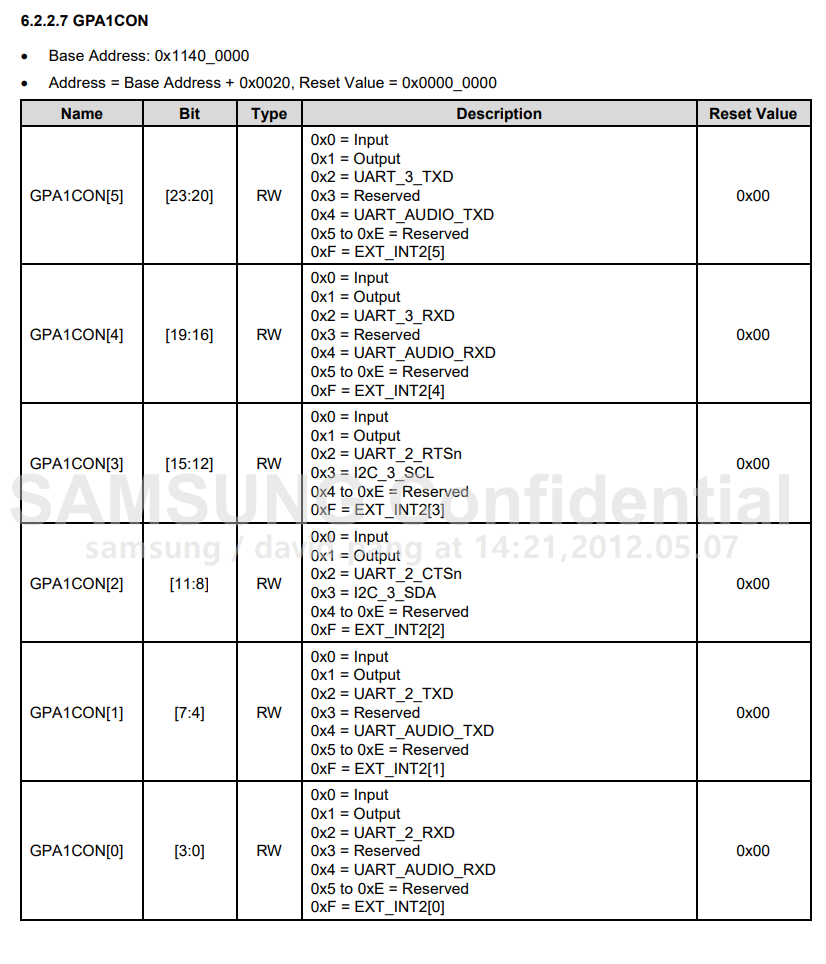
Base Address: 0x1140_0000
Address = Base Address + 0x0020, Reset Value = 0x0000_0000
管脚设置为UART模式:0x11400 0020 = 0x0000 0022
接下来设置串口协议(奇偶校验位,数据位等),查看4412芯片手册目录,找到Universal Asynchronous Receiver and Transmitter(即UART):

查看UART模块介绍:
找到串口协议设置相关寄存器:
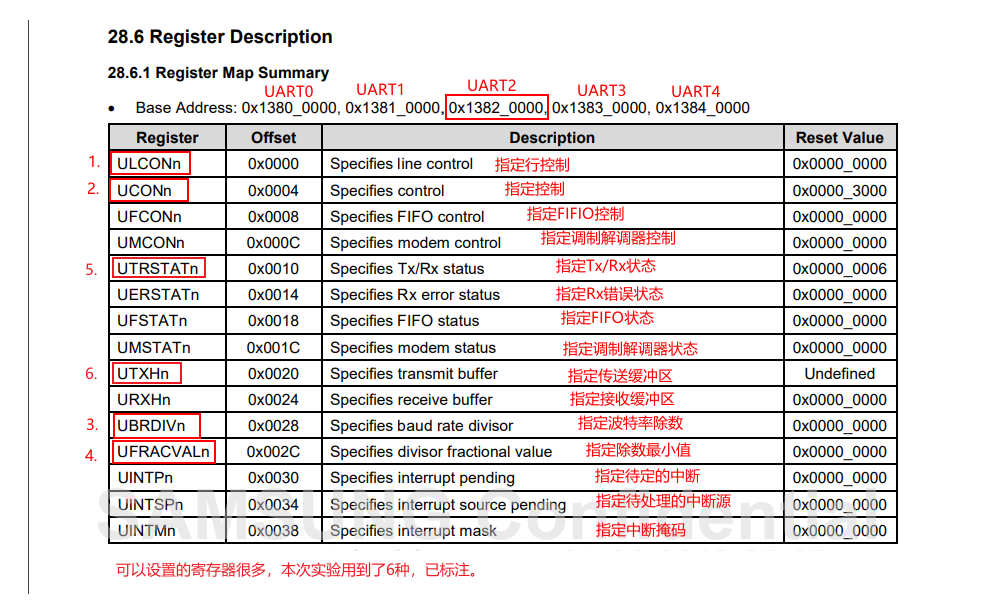
第一个要设置的寄存器 ULCONn寄存器
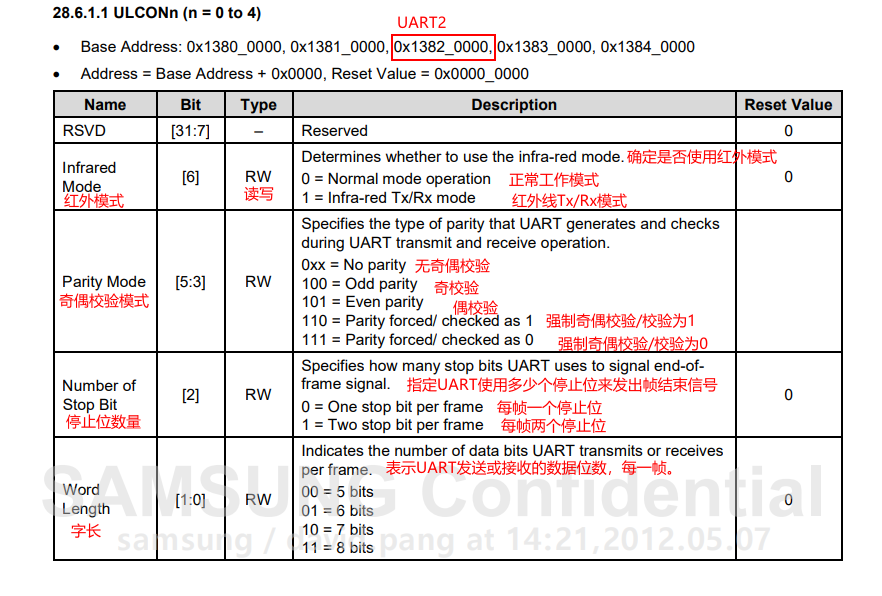
将字长设置为8其余全部默认值即可:0x1382 0000 = 0x0000 0003
第二个要设置的寄存器 UCONn寄存器
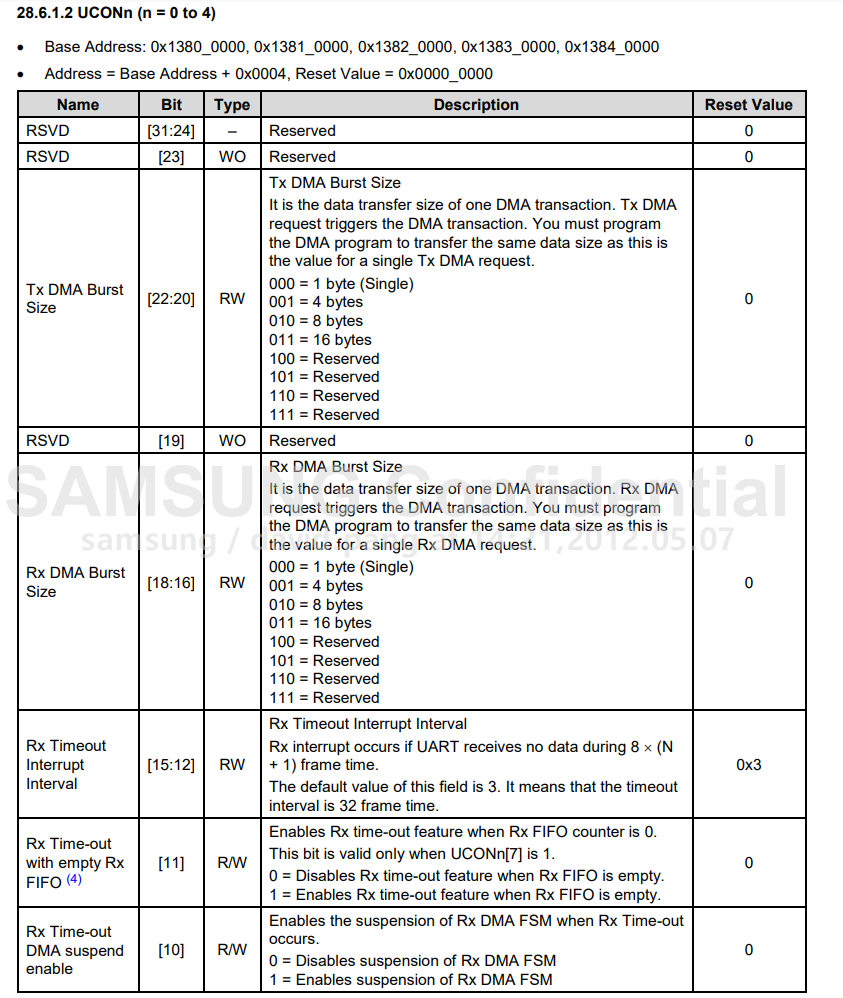
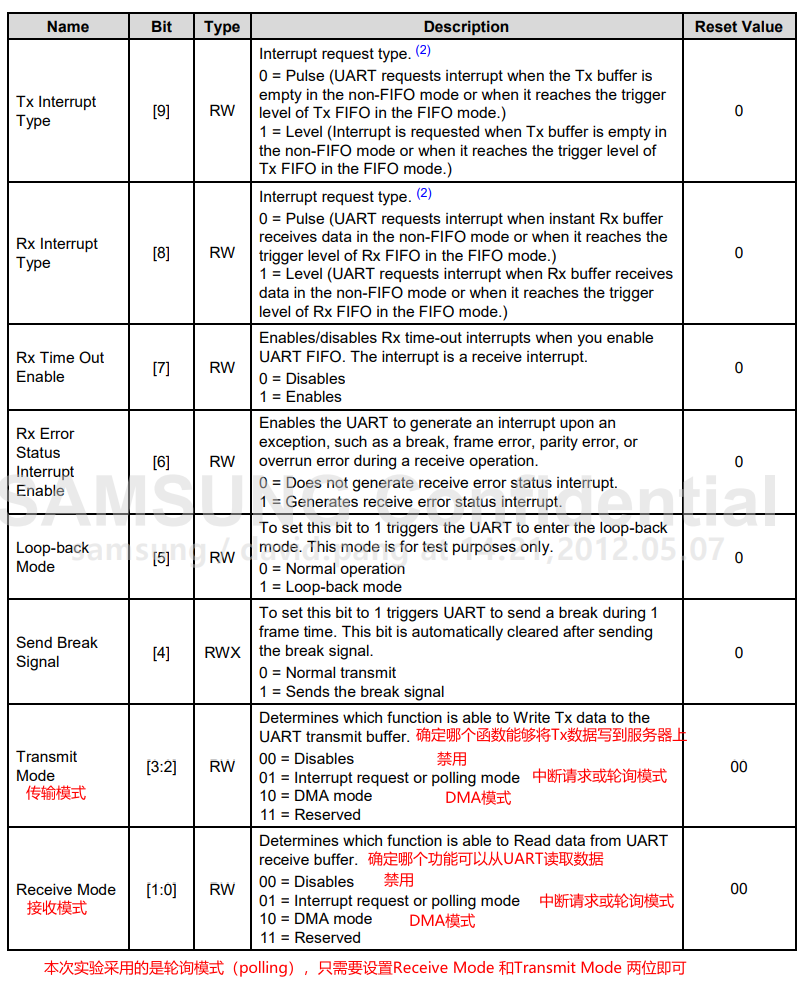
将传输模式改为polling模式,接收模式也改为polling模式。0x1382_0004 = 0x0000 0005
接下来进行波特率的设置:
第三个要设置的寄存器:UBRDIVn

第四个要设置的寄存器:UFRACVALn

第三第四个寄存器值的算法:

查4412手册,查看UART的时钟源频率:
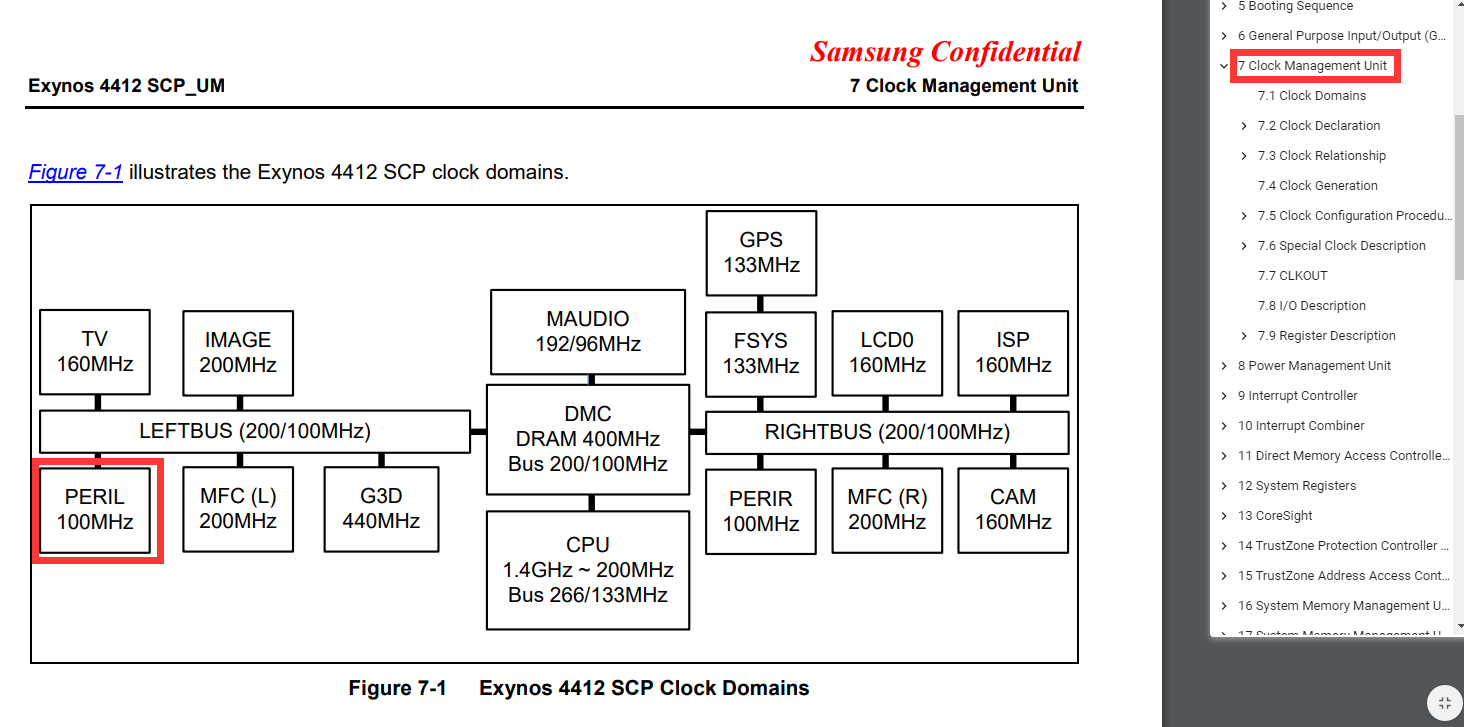
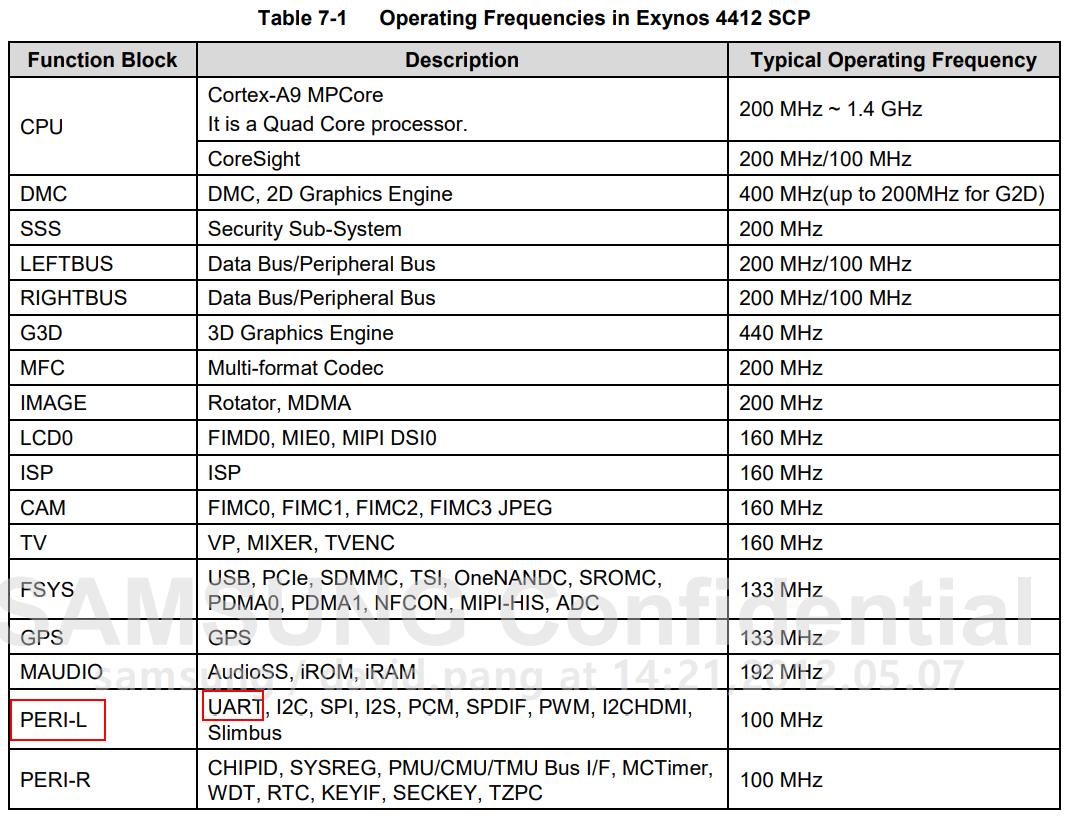
UART时钟信号源的值为:
100Mhz= 100 000khz = 100 000 000hz
本实验波特率值位115200,DIV_VAL = 100000000/(115200*16) -1 = 54.25 -1 = 53.25
UBRDIVn = 53
UFRACVALn/16 = 0.25 ----> UFRACVALn = 4
发送端缓冲区寄存器为UTXH2(Address = 0x1382_0020)

发送端缓冲区状态寄存器为UTRSTAT2 (Addr = 0x1382_0010)
.lds链接文件分析:
本次实验使用的链接文件 map.lds:
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm") /* 指定输出可执行文件是elf格式,32位ARM指令,小端 */
OUTPUT_ARCH(arm) /* 设置输出文件的架构体系为arm架构 */
ENTRY(_start) /* 设置入口点为_start */
SECTIONS /* 段落 */
{
. = 0x40008000; /* 初始地址 */
. = ALIGN(4); /* 四字节对齐 */
.text : /* 代码段 */
{
start.o(.text) /* 从start.o 文件的.text段落开始执行 首先给它分配地址空间*/
*(.text) /* 其余链接文件的.text自动分配地址 */
}
. = ALIGN(4); /* 4字节对齐 */
.data : /* 数据段 */
{ *(.data) } /* 所有链接文件中的数据段均自动分配地址 */
. = ALIGN(4); /* 4字节对齐 */
.bss : /* 未初始化的数据段 */
{ *(.bss) } /* 所有链接文件中的未初始化的数据段均自动分配地址 */
}
.lds文件分析:
对于.lds文件,它定义了整个程序编译之后的连接过程,决定了一个可执行程序的各个段的存储位置。虽然现在我还没怎么用它,但感觉还是挺重要的,有必要了解一下。
先看一下 GNU官方网站上:http://www.gnu.org/
对.lds文件形式的完整描述:
SECTIONS {
secname start BLOCK(align) (NOLOAD) : AT ( ldadr )
{ contents } >region :phdr =fill
}
secname和contents是必须的,其他的都是可选的。下面挑几个常用的看看:
1、secname:段名
2、contents:决定哪些内容放在本段,可以是整个目标文件,也可以是目标文件中的某段(代码段、数据段等)
3、start:本段连接(运行)的地址,如果没有使用AT(ldadr),本段存储的地址也是start。GNU网站上说start可以用任意一种描述地址的符号来描述。
4、AT(ldadr):定义本段存储(加载)的地址。
看一个简单的例子:(摘自《2410完全开发》)
/* nand.lds */
SECTIONS {
firtst 0x00000000 : { head.o init.o }
second 0x30000000 : AT(4096) { main.o }
}
以上,head.o放在0x00000000地址开始处,init.o放在head.o后面,他们的运行地址也是0x00000000,即连接和存储地址相同(没有AT指定);main.o放在4096(0x1000,是AT指定的,存储地址)开始处,但是它的运行地址在0x30000000,运行之前需要从0x1000(加载处)复制到0x30000000(运行处),此过程也就用到了读取Nand flash。
这就是存储地址和连接(运行)地址的不同,称为加载时域和运行时域,可以在.lds连接脚本文件中分别指定。
编写好的.lds文件,在用arm-linux-ld连接命令时带-Tfilename来调用执行,如
arm-linux-ld –Tnand.lds x.o y.o –o xy.o。也用-Ttext参数直接指定连接地址,如
arm-linux-ld –Ttext 0x30000000 x.o y.o –o xy.o。
既然程序有了两种地址,就涉及到一些跳转指令的区别,这里正好写下来,以后万一忘记了也可查看,以前不少东西没记下来现在忘得差不多了。。。
ARM汇编中,常有两种跳转方法:b跳转指令、ldr指令向PC赋值。
我自己经过归纳如下:
(1)
b step1 :b跳转指令是相对跳转,依赖当前PC的值,偏移量是通过该指令本身的bit[23:0]算出来的,这使得使用b指令的程序不依赖于要跳到的代码的位置,只看指令本身。
(2)
ldr pc, =step1 :该指令是从内存中的某个位置(step1)读出数据并赋给PC,同样依赖当前PC的值,但是偏移量是那个位置(step1)的连接地址(运行时的地址),所以可以用它实现从Flash到RAM的程序跳转。
(3)
此外,有必要回味一下adr伪指令,U-boot中那段relocate代码就是通过adr实现当前程序是在RAM中还是flash中。仍然用我当时的注释:
relocate: /* 把U-Boot重新定位到RAM /
adr r0, _start / r0是代码的当前位置 /
/ adr伪指令,汇编器自动通过当前PC的值算出 如果执行到_start时PC的值,放到r0中:
当此段在flash中执行时r0 = _start = 0;当此段在RAM中执行时_start =_TEXT_BASE(在board/smdk2410/config.mk中指定的值为0x33F80000,即u-boot在把代码拷贝到RAM中去执行的代码段的开始) /
ldr r1, _TEXT_BASE / 测试判断是从Flash启动,还是RAM /
/ 此句执行的结果r1始终是0x33FF80000,因为此值是又编译器指定的(ads中设置,或-D设置编译器参数) /
cmp r0, r1 / 比较r0和r1,调试的时候不要执行重定位 */
下面,结合u-boot.lds看看一个正式的连接脚本文件。
OUTPUT_FORMAT("elf32littlearm","elf32littlearm","elf32littlearm")
;指定输出可执行文件是elf格式,32位ARM指令,小端
OUTPUT_ARCH(arm)
;指定输出可执行文件的平台为ARM
ENTRY(_start)
;指定输出可执行文件的起始代码段为_start.
SECTIONS
{
. = 0x00000000 ; 从0x0位置开始
. = ALIGN(4) ; 代码以4字节对齐
.text : ;指定代码段
{
cpu/arm920t/start.o (.text) ; 代码的第一个代码部分
*(.text) ;其它代码部分
}
. = ALIGN(4)
.rodata : { *(.rodata) } ;指定只读数据段
. = ALIGN(4);
.data : { *(.data) } ;指定读/写数据段
. = ALIGN(4);
.got : { *(.got) } ;指定got段, got段式是uboot自定义的一个段, 非标准段
__u_boot_cmd_start = . ;把__u_boot_cmd_start赋值为当前位置, 即起始位置
.u_boot_cmd : { *(.u_boot_cmd) } ;指定u_boot_cmd段, uboot把所有的uboot命令放在该段.
__u_boot_cmd_end = .;把__u_boot_cmd_end赋值为当前位置,即结束位置
. = ALIGN(4);
__bss_start = .; 把__bss_start赋值为当前位置,即bss段的开始位置
.bss : { *(.bss) }; 指定bss段
_end = .; 把_end赋值为当前位置,即bss段的结束位置
}
MAKEFILE文件
all:
arm-none-linux-gnueabi-gcc -fno-builtin -nostdinc -c -o start.o start.S //生成.o汇编文件
arm-none-linux-gnueabi-gcc -fno-builtin -nostdinc -c -o main.o main.c //生成.o汇编文件
arm-none-linux-gnueabi-ld start.o main.o -Tmap.lds -o uart.elf //两个.o汇编文件基于map.lds配置文件合并 生成.elf可GDB调试文件
arm-none-linux-gnueabi-objcopy -O binary uart.elf uart.bin //.elf文件生成.bin二进制文件 用于烧录到开发板
arm-none-linux-gnueabi-objdump -D uart.elf > uart.dis //.elf文件生成.dis反汇编文件方便追踪调试
clean:
rm -rf *.bak start.o main.o uart.elf uart.bin uart.dis
text段、data段和bss段
一般情况,一个程序本质上都是由 bss段、data段、text段三个段组成——这是计算机程序设计中重要的基本概念。而且在嵌入式系统的设计中也非常重要,牵涉到嵌入式系统运行时的内存大小分配,存储单元占用空间大小的问题。
在采用段式内存管理的架构中(比如intel的80x86系统),bss段(Block Started by Symbol segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域,一般在初始化时bss 段部分将会清零(bss段属于静态内存分配,即程序一开始就将其清零了)。
比如,在C语言程序编译完成之后,已初始化的全局变量保存在.data 段中,未初始化的全局变量保存在.bss 段中。
text段: 用于存放程序代码的区域, 编译时确定, 只读。更进一步讲是存放处理器的机器指令,当各个源文件单独编译之后生成目标文件,经连接器链接各个目标文件并解决各个源文件之间函数的引用,与此同时,还得将所有目标文件中的.text段合在一起,但不是简单的将它们“堆”在一起就完事,还需要处理各个段之间的函数引用问题。
在嵌入式系统中,如果处理器是带MMU(MemoryManagement Unit,内存管理单元),那么当我们的可执行程序被加载到内存以后,通常都会将.text段所在的内存空间设置为只读,以保护.text中的代码不会被意外的改写(比如在程序出错时)。当然,如果没有MMU就无法获得这种代码保护功能。
data段 :用于存放在编译阶段(而非运行时)就能确定的数据,可读可写。也是通常所说的静态存储区,赋了初值的全局变量、常量和静态变量都存放在这个域。
而bss段不在可执行文件中,由系统初始化。
bss段(未手动初始化的数据)并不给该段的数据分配空间,只是记录数据所需空间的大小。
data段(已手动初始化的数据)为数据分配空间,数据保存在目标文件中。
data段包含经过初始化的全局变量以及它们的值。
BSS段的大小从可执行文件中得到,然后链接器得到这个大小的内存块,紧跟在数据段后面。当这个内存区进入程序的地址空间后全部清零,包含data和bss段的整个区段此时通常称为数据区。